kpl回溯怎么实现?
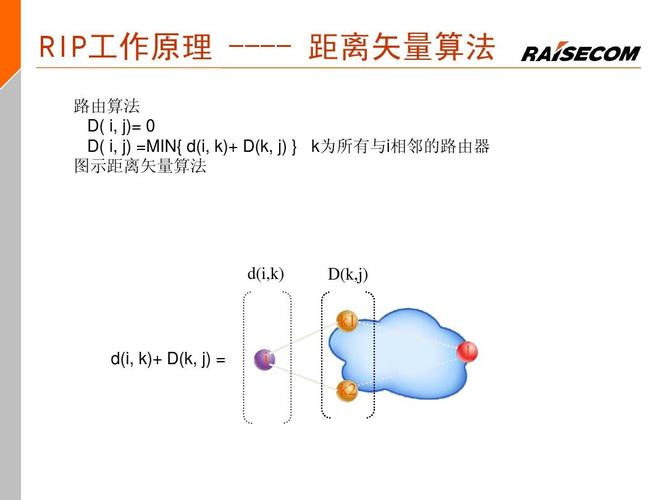
您好,kpl回溯是一种基于回溯算法的搜索算法。其实现的基本思路是:从起点出发,按照一定的规则扩展搜索路径,直到找到解或者无法继续扩展路径,然后回溯到上一个节点,尝试其他路径,直到所有路径都被搜索完毕。

具体实现可以按照以下步骤:
1. 定义一个状态表示节点的数据结构,包括当前节点的值、当前节点的状态、当前节点的父节点等信息。
2. 定义一个搜索函数,输入为当前节点和目标节点,输出为是否找到目标节点。在搜索函数中,首先检查当前节点是否为目标节点,如果是则返回true;否则遍历当前节点的所有子节点,将其状态设置为已访问,并将其加入搜索队列中。然后递归调用搜索函数,如果子节点搜索到目标节点,返回true,否则将子节点状态设置为未访问,并从搜索队列中移除该节点。

3. 在搜索函数中,如果所有子节点都被搜索完毕,返回false,表示无法找到目标节点。此时需要回溯到父节点,尝试其他子节点。
4. 可以选择使用递归或者循环来实现搜索函数。如果使用递归,需要注意设置递归终止条件,避免出现无限递归的情况;如果使用循环,需要使用队列来存储节点。
5. 在搜索过程中,需要记录搜索路径,可以使用栈来存储路径,每次进入新的节点时将该节点加入栈中,回溯时从栈中弹出节点。

6. 可以选择使用剪枝优化搜索过程,例如设置最大深度、最大搜索次数等限制条件,避免搜索过程过于耗时。
以上就是kpl回溯的基本实现思路,根据具体情况可以进行适当的调整和优化。
KPL回溯可以通过以下步骤实现。
KPL回溯可以通过回溯算法实现。
回溯算法是一种可以枚举所有可能情况的算法,通过不断回溯到上一步,尝试其他可能解决方案来达到目标。
KPL回溯也是通过不断尝试每一种可能性,直到找到最优方案。
在KPL比赛中,若出现了某个选手的掌控能力超过另一个选手的情况,可以通过KPL回溯来恢复平衡。
在进行KPL回溯时,需要确定回溯的起点和目标,以及每一步的操作,经过多次尝试和迭代,可以得到最优解。
同时,KPL回溯过程中,需要考虑时间和空间的效率,避免出现超时或超空间的情况。
1 KPL回溯实现是可行的。
2 实现KPL回溯需要对问题进行分析,确定变量和约束条件,然后进行递归搜索,如果发现不满足某个约束条件,则回溯到上一个状态,继续搜索。
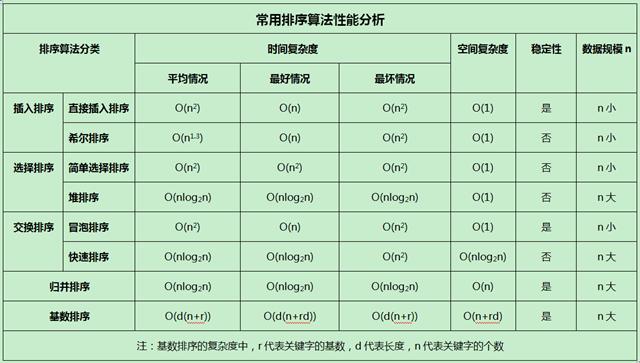
KPL回溯的速度和效率较高,可以用于解决一些NP难问题,如n皇后问题等。
3 在实现KPL回溯的过程中,需要注意剪枝操作的使用,以减少无效搜索,提高算法效率。
此外,对于大规模问题,还需要使用并行计算等技术来加速搜索过程。
KPL回溯功能是基于消息轨迹存储的日志,可以查看消息在KPL驱动、服务端、KCL应用程序每一步的详细情况。KPL回溯功能的实现需要在发送消息时开启轨迹追踪,然后在控制台中选择所需的日志,进行查看。
具体实现步骤如下:
1. 在消息发送时开启轨迹追踪,设置TraceId、SpanId等相关属性。
2. 确保KPL驱动和KCL应用程序使用的是相同的TraceId,在驱动和KCL程序的配置文件中设置相应的参数。
3. 配置消息轨迹存储,可以选择存储在本地或者使用Kinesis Data Firehose将日志存储在S3中。
4. 在控制台中选择需要查看的KPL日志,可以按照时间、应用程序等过滤查看。
需要注意的是,KPL回溯功能会对消息生产的性能造成影响,因此应该根据实际业务需求选择是否启用该功能。
到此,以上就是小编对于windows枚举进程模块的问题就介绍到这了,希望介绍的1点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏