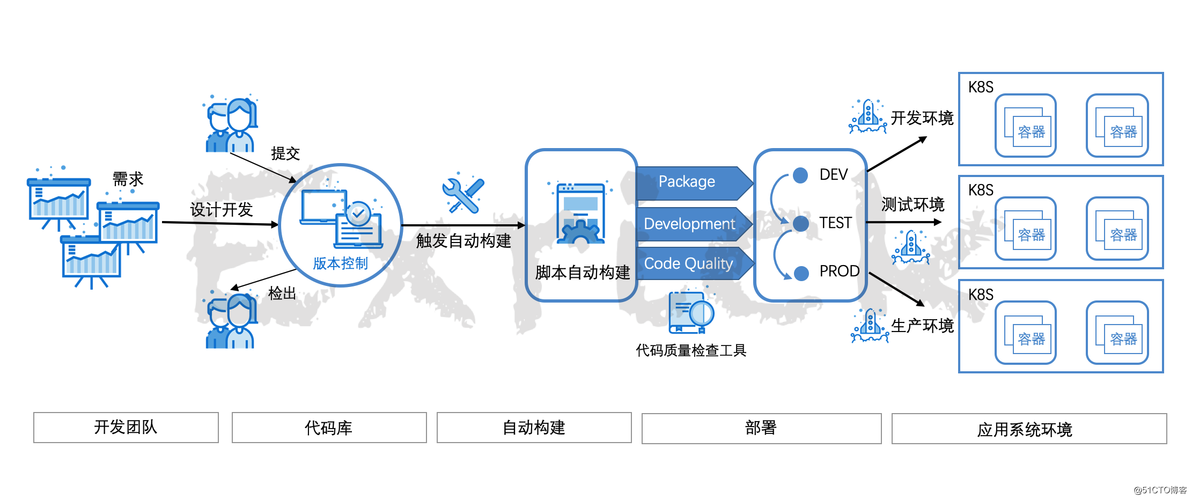
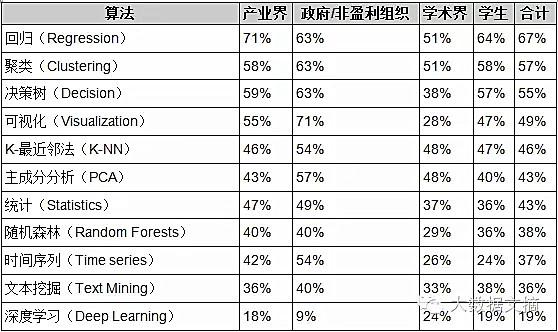
传统大数据的三种架构?
关于这个问题,传统大数据的三种架构分别是:
-图1")
1. 批处理架构(Batch Processing Architecture):批处理架构是最常见的大数据架构之一,它通过将大量数据一次性加载到内存中进行处理和分析。这种架构适用于对数据进行离线分析,处理时间可以比较长,但可以处理大规模的数据集。典型的批处理架构包括Hadoop MapReduce和Apache Spark。
2. 流处理架构(Stream Processing Architecture):流处理架构是一种实时处理大数据的架构,它可以对数据进行连续的实时处理和分析。与批处理不同,流处理可以在数据到达时立即进行处理,适用于需要实时响应和即时决策的应用场景。常见的流处理架构包括Apache Flink和Apache Kafka Streams。
3. 交互式查询架构(Interactive Querying Architecture):交互式查询架构是一种用于快速查询和分析大规模数据集的架构。它通常使用分布式数据库或数据仓库来存储和管理数据,并提供快速的查询和分析功能。交互式查询架构适用于需要快速查询和分析数据的应用场景,如数据探索、数据可视化和业务智能。常见的交互式查询架构包括Apache Hive和Apache Impala。
-图2")
传统大数据存储系统通常有以下三种架构:
1. 单机存储架构:这种架构使用单个服务器来存储和处理大数据。它通常包括一个主服务器和多个从服务器,主服务器负责数据的输入、处理和管理,而从服务器用于存储数据和执行计算任务。单机存储架构适用于小规模的数据存储和处理需求,但在面对大规模数据和高并发访问时可能存在性能瓶颈。
2. 分布式存储架构:这种架构将数据分布在多个服务器上,以实现数据的分片存储和并行处理。每个服务器都负责存储和处理一部分数据,通过分布式文件系统或分布式数据库管理数据的分布和访问。分布式存储架构可以提供更高的数据处理能力和可扩展性,适用于大规模的数据存储和处理需求。
-图3")
3. 多层存储架构:这种架构将数据分为多个层级,并根据数据的访问频率和重要性将其存储在不同的介质上。通常包括快速存储层(如内存或固态硬盘)用于存储热数据,以及较慢的存储层(如磁盘)用于存储冷数据。多层存储架构可以在满足性能需求的同时节省存储成本,提高数据的访问效率。
这些传统大数据存储系统架构各有优缺点,选择适合的架构取决于具体的数据存储和处理需求,以及预算和性能要求。近年来,随着云计算和分布
大数据岗位分类?
1 大数据岗位主要分为以下几类:
- 大数据工程师:负责数据采集、存储、处理、分析等技术实现;
- 大数据开发工程师:负责大数据平台的开发和维护;
- 大数据架构师:负责设计和指导大数据平台的整体架构;
- 大数据分析师:负责对大数据进行分析和挖掘,为决策提供支持;
- 数据科学家:负责深入分析和研究数据,提出解决方案和预测模型。
2 这些岗位分类是根据大数据行业的需求和任务来分的,每个岗位都有不同的职责和技能要求。
3 如果想成为大数据从业人员,可以根据自身兴趣和职业规划选择相应的岗位,同时也需要不断学习和提升自己的技能。
到此,以上就是小编对于大数据框架有哪些类型的问题就介绍到这了,希望介绍的2点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏