常见的六大聚类算法?
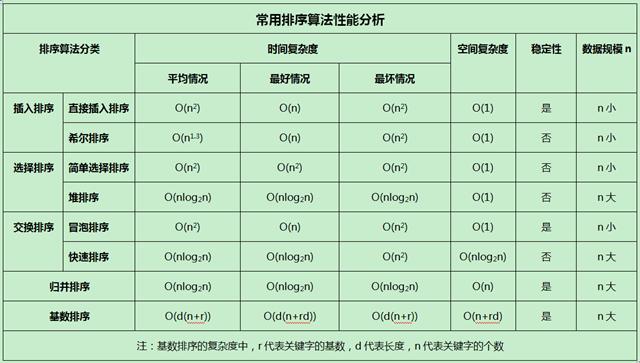
1. 常见的六大聚类算法分别为K-Means、DBSCAN、层次聚类、密度聚类、谱聚类、BIRCH。
-图1")
2. 六大聚类算法是目前常见的聚类算法,其中每个算法都有着各自的特点和适用范围。
3. 例如K-Means聚类算法是一种基于质心的聚类算法,简单易懂,适用于数据分布相对均匀的情况;而DBSCAN聚类算法则是一种基于密度的聚类算法,适用于发现任意形状的分类簇,并能有效地去除噪声点。
以下是常见的六大聚类算法:
-图2")
1. K均值聚类算法:K均值聚类算法是一种基于距离度量的聚类方法,其目标是将数据分为K个簇,使得同一簇内的数据彼此相似度较高,而不同簇之间的数据相似度较低。
2. 层次聚类算法:层次聚类算法是一种基于树形结构的聚类方法,其目标是将数据分为一系列层次结构中的簇,每个簇都包含一个或多个数据点。层次聚类算法分为自上而下和自下而上两种类型。
3. 密度聚类算法:密度聚类算法是一种基于密度的聚类方法,其目标是将数据分为密度相似的簇。密度聚类算法通常需要设置参数(例如密度阈值)来确定簇的数量和大小。
-图3")
4. 均值漂移聚类算法:均值漂移聚类算法是一种基于密度的聚类方法,其目标是在密度高的区域中寻找数据点的聚集中心,并将其作为簇的中心点。均值漂移聚类算法通常需要设置参数(例如带宽)来确定簇的数量和大小。
5. 谱聚类算法:谱聚类算法是一种基于图论的聚类方法,其目标是将数据分为一定数量的簇,使得同一簇内的数据点之间的相似度较高,而不同簇之间的相似度较低。谱聚类算法通常需要计算数据点之间的相似度矩阵,并将其转换为拉普拉斯矩阵进行聚类。
6. DBSCAN聚类算法:DBSCAN聚类算法是一种基于密度的聚类方法,其目标是将数据分为一定数量的簇,使得同一簇内的数据点相似度较高,而不同簇之间的相似度较低。DBSCAN聚类算法不需要预先设置簇的数量,而是通过密度阈值和邻域半径来确定簇的大小和数量。
系统聚类和动态聚类的方法?
系统聚类是将个样品分成若干类的方法,其基本思想是:先将个样品各看成一类,然后规定类与类之间的距离,选择距离最小的一对合并成新的一类,计算新类与其他类之间的距离,再将距离最近的两类合并,这样每次减少一类,直至所有的样品合为一类为止。
动态聚类法亦称逐步聚类法。一类聚类法,属于大样本聚类法.具体作法是:先粗略地进行预分类,然后再逐步调整,直到把类分得比较合理为止,这种分类方法较之系统聚类法,具有计算量较小、占用计算机存贮单元少、方法简单等优点,所以更适用于大样本的聚类分析。 动态聚类法的聚类过程,可用以框图来描述,框图的每一部分,均有很多种方法可采用,将这些方法按框图进行组合,就会得到各种动态聚类法。
系统聚类分析步骤?
系统聚类的步骤一般是首先根据一批数据或指标找出能度量这些数据或指标之间相似程度的统计量;然后以统计量作为划分类型的依据,把一些相似程度大的变量(或样品)首先聚合为一类,而把另一些相似程度较小的变量(或样品)聚合为另一类,直到所有的变量(或样品)都聚合完毕,最后根据各类之间的亲疏关系,逐步画成一张完整的分类系统图,又称谱系图。其相似程度由距离或者相似系数定义。进行类别合并的准则是使得类间差异最大,而类内差异最小。
特点:事先无须知道分类对象的分类结构,而只需要一批地理数据;然后选好分类统计量,并按一定的方法步骤进行计算;最后便能自然地、客观地得到一张完整的分类系统图。
到此,以上就是小编对于聚类分析有哪些方法和技巧的问题就介绍到这了,希望介绍的3点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏