数据挖掘四种决策树模型的特点?
数据挖掘中常用的四种决策树模型包括ID3、C4.5、CART和随机森林。
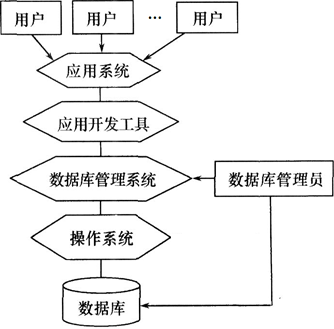
-图1")
ID3和C4.5适用于分类问题,能够处理离散和连续特征,但C4.5能处理缺失值。CART可用于分类和回归问题,能处理离散和连续特征,且能处理缺失值。
随机森林是一种集成学习方法,通过构建多个决策树并进行投票或平均来提高预测准确性,适用于分类和回归问题,且能处理大规模数据。
这些模型都易于理解和解释,但对于高维数据和噪声敏感。
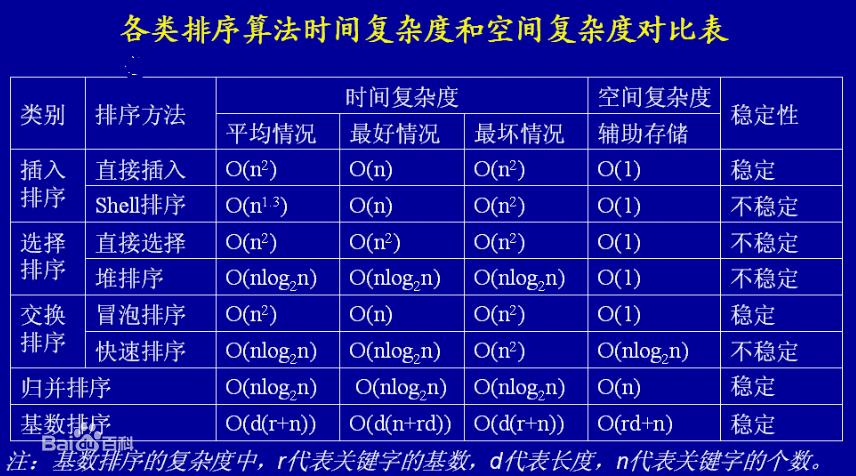
-图2")
决策树算法本身的特点使其适合进行属性数(特征数)较少情况下的高质量分类,因而适用于仅仅利用主题无关特征进行学习的关键资源定位任务。
决策树算法的核心问题是选取在树的每个结点即要测试的属性,争取能够选择出最有助于分类实例的属性.为了解决这个问题,ID3算法引入了信息增益的概念,并使用信息增益的多少来决定决策树各层次上的不同结点即用于分类的重要属性。
什么是数据挖掘竞赛?
1.数据挖掘竞赛是指:从海量数据中找到有意义的模式或知识的一类专业竞赛。
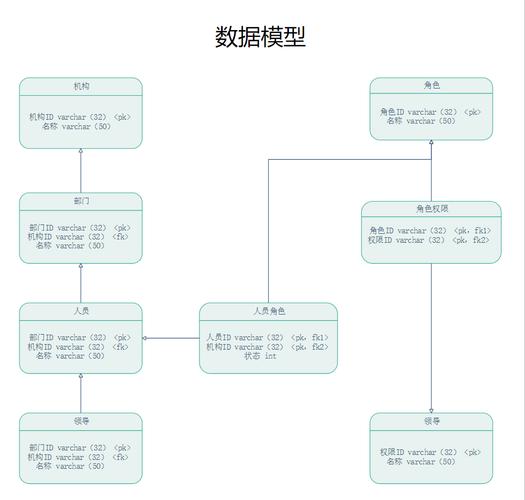
-图3")
2.数据挖掘竞赛涉及到很多的算法,有源于机器学习的神经网络,决策树,也有基于统计学习理论的支持向量机,分类回归树,和关联分析的诸多算法。
3.数据挖掘竞赛内容就是:反复做数据观察, 反复增剪特征(需要领域知识和运气), 反复尝试各种各种模型,要进行各种各样的尝试,发掘有益数据和知识。所以工程代码量会很大。
随着人工智能的发展,越来越多的公司开始举办数据挖掘竞赛比赛,题目类型也越来越丰富。
数据挖掘的主要方法?
数据挖掘的基本步骤是:1、定义问题;2、建立数据挖掘库;3、分析数据;4、准备数据;5、建立模型;6、评价模型;7、实施。
具体步骤如下:
1、定义问题
在开始知识发现之前最先的也是最重要的要求就是了解数据和业务问题。必须要对目标有一个清晰明确的定义,即决定到底想干什么。比如,想提高电子信箱的利用率时,想做的可能是“提高用户使用率”,也可能是“提高一次用户使用的价值”,要解决这两个问题而建立的模型几乎是完全不同的,必须做出决定。
2、建立数据挖掘库
建立数据挖掘库包括以下几个步骤:数据收集,数据描述,选择,数据质量评估和数据清理,合并与整合,构建元数据,加载数据挖掘库,维护数据挖掘库。
3、分析数据
分析的目的是找到对预测输出影响最大的数据字段,和决定是否需要定义导出字段。如果数据集包含成百上千的字段,那么浏览分析这些数据将是一件非常耗时和累人的事情,这时需要选择一个具有好的界面和功能强大的工具软件来协助你完成这些事情。
4、准备数据
这是建立模型之前的最后一步数据准备工作。可以把此步骤分为四个部分:选择变量,选择记录,创建新变量,转换变量。
1、分类。分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。
它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。
2、回归分析。回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。
到此,以上就是小编对于数据挖掘有哪些模型组成的问题就介绍到这了,希望介绍的3点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏